去年,科学界建立了数千个机器学习模型和其他人工智能系统,以在胸部X光和CT图像上识别新冠病毒。一些研究人员对研究结果表示怀疑:这些模型是识别了新冠病毒的病理,还是基于混杂因素(如箭头和其他医学无关的特征)做出决策?
为了回答这个问题,两名医学院学生在华盛顿大学李秀英(Su-In Lee)的实验室攻读计算机科学博士学位,他们严格审计了数百个用于将胸部X光片分类为新冠病毒阳性或阴性的机器学习模型。他们的审计结果发表在《自然机器智能》杂志上。
畴移问题
华盛顿大学的研究人员想知道发表的机器学习(ML)模型是否具有通用性。一种通用的ML模型,无论胸部x光片来自哪里,都能正确地将其划分为新冠病毒阳性或阴性。一个不能推广的模型就不能很好地发挥作用,例如,当它看到在另一家医院获得的胸部X光片时。
计算机科学家称这种性能下降为域转移。受域移影响的机器学习模型能实时发现数据集之间的系统性差异,对模型来说,这些差异比新冠病毒感染的细微迹象更强、更明显。然后,这些ML模型采用了捷径学习,在混淆物(如箭头和文本标签)上进行训练,甚至在其他数据集中对模型进行训练和测试时也会产生虚假的关联。
通过这种方式,使用快捷学习的ML模型将会显示出域的变化,并且不能一般化,而依赖医学相关特征做出决策的ML模型更有可能一般化,并在跨数据集保持其性能。
审计,机器学习风格
虽然用于胸片分类的ML模型往往使用类似的架构、训练方法和优化方案,但华盛顿大学研究人员面临的第一个障碍是重新创建已发表的ML模型。
华盛顿大学研究报告的第一作者之一亚历克斯·德格雷夫(Alex DeGrave)说:“模型可以在微妙的方面有所不同……研究人员不是分发训练过的模型,而是给出如何制作模型的指导。”“由于(模型)训练过程的随机性,你最终可能会从这一套方向中摆脱出一系列模型。”
为了反映培训过程中可能出现的变化,共同第一作者DeGrave和Joseph Janizek,以及他们的顾问和资深作者suin Lee,首先设计了一个代表数十项研究中引入的ML模型,然后对这个代表模型进行了微小的调整。他们最终创建并审计了数百个模型,并对数千张胸部x光片进行了分类。
是新冠病毒还是一个箭头?
在将他们的模型引入到新的数据集之后,研究人员观察到域漂移和捷径学习导致分类性能下降,于是决定自己找出捷径。这是一个挑战,因为ML模型做出的决策来自于一个“黑盒子”——这些模型如何做出分类决策甚至对模型设计者来说都是未知的。
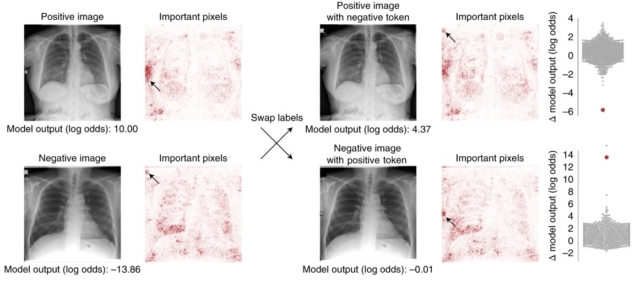
DeGrave和Janizek利用突出显示模型认为重要的区域的显著地图解构了这个“黑盒子”,运用生成方法转换图像,并通过手工编辑图像。一些显著性地图显示与医学相关的区域,如肺部,而另一些则指向图像上的文本或箭头,或图像的角落,这表明ML模型基于这些特征而不是病理来学习和确定新冠病毒状态。
为了验证这些结果,研究人员应用生成法使新冠病毒阴性胸片看起来像新冠病毒阳性胸片,反之亦然。
迪格雷夫解释说:“我们发现,如果我们回去把这些(修改过的)图像输入我们审计的原始网络,通常会让那些网络误以为它们是来自相反类别的图像。”“因此,这意味着这些生成网络正在改变的东西确实是我们正在审核的网络。”
研究人员再次发现,当他们在成对的图像(一组新冠病毒阳性和一组新冠病毒阴性胸片)上交换书面文本时,模型的表现取决于文本标记。研究人员的实验还表明,模型架构对模型性能的影响很小。
“我认为,在文学中有很多关注,‘我们有最好的,最有趣的新建筑’。我们发现这实际上只有有限的影响……而处理数据,修改数据,收集更好的数据,却有相当大的影响,”Janizek说。
构建和审计可信的AI系统
研究结果表明了捷径学习的重要性。它们还指出了对可解释人工智能的需求,这要求机器学习模型做出的决策能够被人类理解和追踪,并继续向前发展。
那么,研究人员如何构建机器学习网络,从医学相关的特征中学习,并一般化?
DeGrave和Janizek提供了一些建议。首先,研究人员应该前瞻性地收集数据,并牢记模型的目标,数据集应该具有良好的重叠性。例如,参与研究的每个机构应该收集新冠病毒阳性和阴性数据,而不是其中一种。其次,临床医生应该参与研究设计和数据收集,研究人员应该与临床医生一起识别ML模型可能依赖的不同种类的混杂因素。第三,在将ML模型应用到其他地方之前,应该对其进行审计。
研究人员说,这些建议本身不足以克服捷径学习,还需要更多的研究。目前,他们希望这项研究能引发更广泛的对话,讨论审计ML模型的重要性以及可解释人工智能的必要性。他们还希望人们对机器学习模型可能犯的错误有更多的认识。
“有方法来解释模型和检测捷径,也有方法来试图改进模型……研究人员需要真正思考所有这些方法是如何相互联系的,从而不仅仅是建立更好的方法,而是一个更好的方法生态系统,这些方法相互连接,使模型开发者更容易建立一个我们可以信任和依赖的模型,”Janizek说。